Yesterday I watched an excellent video tutorial about startup growth tactics by Adora Cheung, a guest lecturer in Sam Altman’s startup class. The speaker has experience from user-testing 13 business ideas so you can tell she knows what she’s talking about. Growth, cohort analysis, and segmentation are all essential tools startup founders should know about.
It made me think about how little analytics I’ve been doing for minireference.com and this blog. What happens when a visitor comes to the homepage? Do they read the whole page? Do they click on any of the questions? Do they download the free PDF tutorials? Most important of all, do they click on one of they Buy links.
Let’s find out…
I previously evaluated the effectiveness of the landing page and found 3-4% conversion rates for the print book and similar rates for the Buy PDF link, and I remember being pleased about those numbers.
These days I see similar numbers: combined Print+PDF conversion is ~= 7.7%.
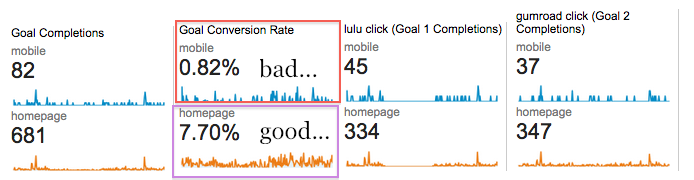
Looks good right? (Please, ignore the abysmal mobile conversion rates. I’m on bootstrap2 and everything will be fixed when I upgrade to bootstrap3 in a few weeks.)
The problem is many potential readers drop off after clicking through to lulu.com and gumroad.com. I lose contact with my potential customers as soon as they leave my site, so I don’t know how many of them actually bought something. Today I set out to calculate my real conversion rates by cross correlating the data form the google analytics, lulu.com, and gumroad.com.
Burst analysis
My main “marketing channel” is hacker news. Each time I release a new printable PDF tutorials, I post it to HN. It’s an elaborate ploy to gain readers’ trust by gifting them something useful (e.g. a 4-page printable tutorial) and upsell them to buy one of the books. I consider this to be ethical advertisement.
Because of this mono-site marketing strategy, the traffic on minireference.com is generally calm, but every now and then there is a huge spike that occurs when I post something to HN. This bursty nature of the traffic allows us to do a deeper analysis of the conversion rates.
Using google analytics, The visitors, and the two conversions goals are plotted below:
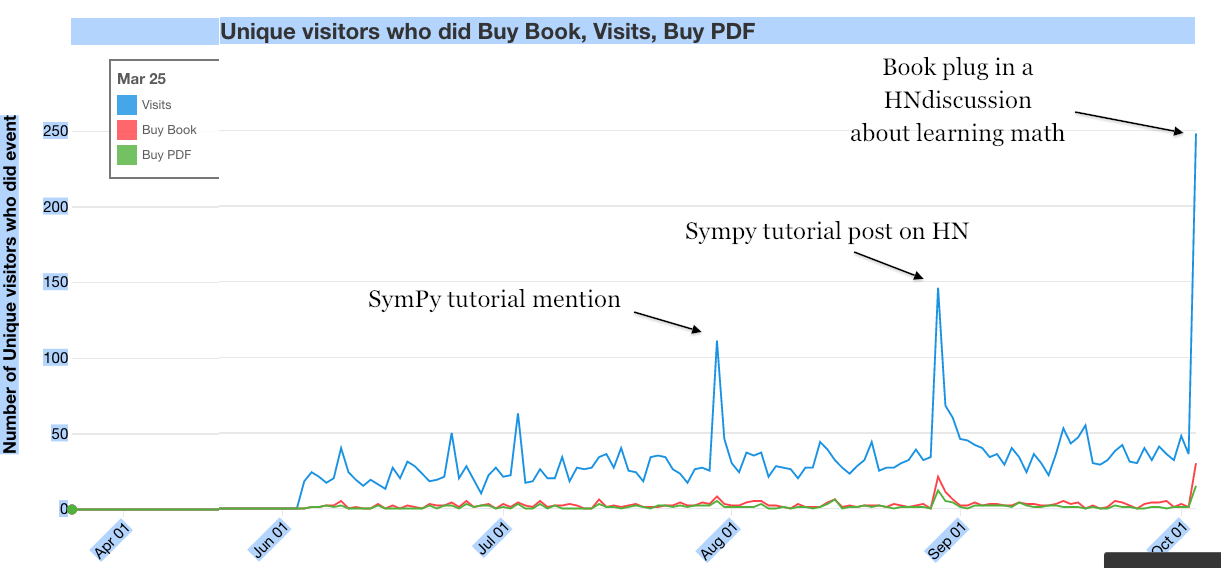
I chose to analyze the events surrounding two bursts of Aug 29th and Oct 3rd. The Aug 29th spike is thanks to the announcement of the
SymPy tutorial on HN.
I was able to calculate the post-minireference.com conversion rate for the print book:
Buy book link --> ordered from lulu: 14%(3/21) on Aug 29 and 10%(3/29) on Oct 3
The post-minireference.com conversion rate for the PDF is:
Buy PDF link --> ordered from gumroad: 33%(3/12) on Aug 29 and 21%(3/14) on Oct 3
Not cool y’all! I better work on this. What do people not like about lulu.com? Is it because they’re not used to it, should I put an Amazon link there?
What are dem visitors doing?
Another question that’s pertinent is how far down the page to users scroll.
We can obtain this information from the graph of scroll-depth events from google analytics (I have some .js the fires events at 0% (baseline), 25%, 50%, and 100% scroll depth.
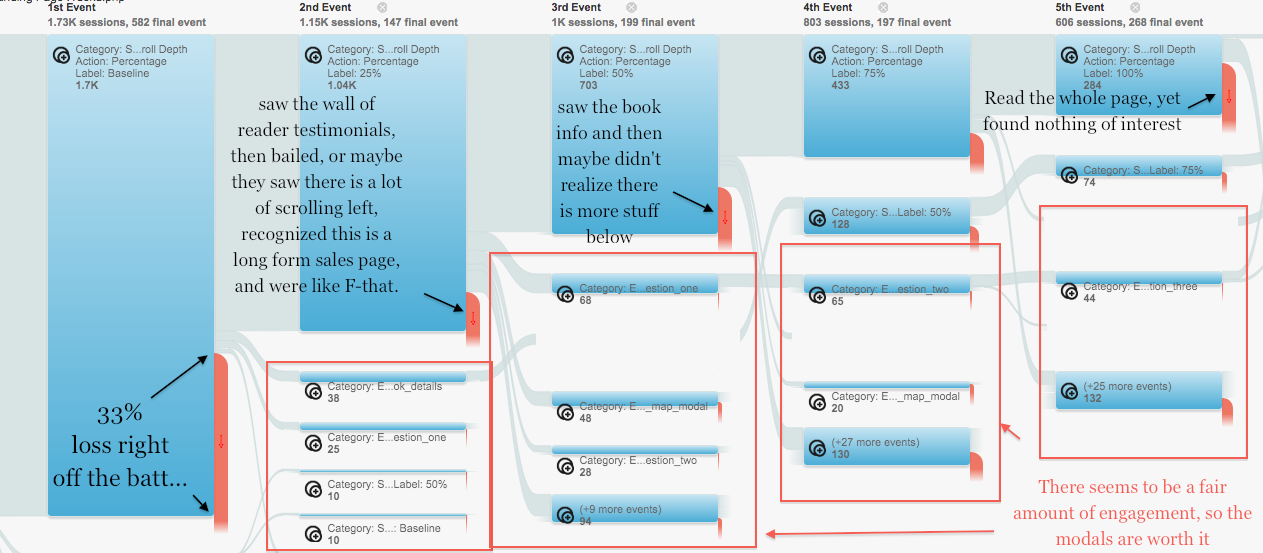
It’s hard to read anything from that graph, but I’m saving the data for posterity—I want to have something to compare with when I switch to the new landing page…
Does the free tutorial marketing strategy work?
It took me more than a mont of part-time work to write the SymPy tutorial. It’s almost like a little book, since it covers so many topics. I also incurred $90 in copy-editing costs to make sure the writing is solid, since the tutorial was to become an appendix in the book. Was this effort worth it? Let’s see the traffic that resulted.
A total of 10k people downloaded the PDF. I had to use the server logs to get this data, because many people linked directly to the PDF, which means google analytics won’t see these hits. Using zgrep and wc the count the number of lines in the logs that contain the pdf url and HTTP code 200:
zgrep '"GET /static/tutorials/sympy_tutorial.pdf HTTP/1.1" 200' mr.access.log mr.access.log* | wc 10058 203840 2369042 ^^^^^
The initial link to HN pointed to the blog post announcement, so we can see some part of that traffic on the blog:

Ultimately, what is of interest is how much traffic to minireference.com did the SymPy tutorial generate. We see the tutorial led to a spike of about 300 visitors to the main page.

From the numbers we have so far, we can estimate the conversion rate for the referral strategy via free PDF tutorials to be 3% = 300/10000. The SymPy tutorial also led to a “livelying” effect of the traffic in the following days, as can be seen in the graph. Clearly, more people are hearing about minireference.com and coming to check out the site.
The final profit from sales for this spike is \$150 so I’ve recouped the external expenses, and earned a salary of \$60/month, which is not great but still positive. The 3% conversion rate is very interesting, IMHO. I’ll pursue this strategy further, because it has great potential for viral growth—wouldn’t you send a kick-ass PDF tutorial on subject X to your classmates? (caveat: some engineering schools grade “on the curve” so for these students, it is actually game-theoretically disadvantageous to share quality learning material with their peers)
Conclusions and further research
The purpose of this blog post was to reduce the level of guilt I felt about not playing enough with analytics for my web properties. I feel I’ve achieved some level of guilt-diminishment and, more importantly, now I’ve got numbers that I can use as the baseline for comparison with the new homepage. Surely the conversion rates can be improved; the book is great, I just need to have simple messaging that explains how great the book is, and how it is good value-for-money for students, and also good knowledge-buzz-delivered-per-unit-time for adult learners.
Questions to followup on:
- How many landing pages do I need? There are essentially three “touching points” with my potential readers. A cold visit to the homepage (e.g. google search), a warm visit to the homepage (via recommendation), a tutorial referral visitor (which is super warm). Will the same marketing message work for all three types of traffic, or should I have three landing pages?
- What is the optimal order of the sales pitch? (A/B/../Z-test of section ordering.
- Should each book have its own landing page (/noBSmath and /noBSLA) or focus on a single page with two products?
- A/B test lulu.com vs amazon.com for the “Buy Book” link.
- What channels to develop next?
Okay, enough blogging. Let’s go write some kick-ass marketing copy. And from now on, we’ll be tracking them sales!
{kind=link}