It has been a long time since I last wrote something, but I haven’t been idle altogether. I’ve been planning what to do next for the books, calculating my move, so to say. It’s slowly starting to become clearer. Given my background as linux sysadmin and tutor, it only makes sense if the revolution looks to me like an open source software stack for schools. Read on to find the general strategy. Listen to this good tune if you’re missing an accompanying soundtrack; here is some more tunes in case the blog post ends up long.
I’m going to write a toolbox for every school out there to print their own textbooks and other educational material.
The best-in-class existing exercise framework is already available as open source and can be hosted on the school’s server (or virtual on AWS for $40/mo), but since we’re going to have a “school server,” wouldn’t we want to run some other stuff on there too?
I’m thinking:
- printable exercises sheets for doing in class
- printable problems to give as homework
- printable exams (different version for each student)
- print affordable textbooks (using POD service like lulu.com)
I’m happy for all the kids with iPods and computers at home, but not every school has the budget for computers, so let’s try to keep the costs to at most $20 per class for the week. A few good laser printers could keep the school running with students learning from top notch material, at the cost of a few thousand dollars per month. Toner and paper.
Okay, but where are you going to get the content.
There’s plenty of OER out there, but there could be more and it could be made more easily accessible.
Content framework
Here I must confess, I will be biased, because as a django person, I see the world through my own prism. A very good way for presenting structured content exists already, as free software. That’s the best place to start. Everything else on the content management side, and exporting printable PDFs I can script myself. The main content pipeline will be something like .md --> .tex --> .pdf; the softcover/polytexnic toolchain is very good at this.
UX
The key is to make it easy for teachers to browse, use, and contribute content. The graph structure (and possible common core math categorization) will help the browsing, the .toPDF() methods will make the content immediately usable, and the only real problem remaining is the user experience that entices teachers to contribute content. That’s the biggie. But it can be done.
Software requirement specification
Given a collection of content items (paragraphs of text, entire sections of book, exercises, or problems), the system allows teachers to assemble custom “playlists” which consists of a sequence of content items with a `.toPDF` method.
No way I’m going to let them run the high schools. We’re taking over that business too now.
Aren’t big publishers better?
The market forces will prevail. What is better for a cash-strapped school, to order some crusty mainstream algebra textbook, that may or may not be standard-compliant, but sure is long and talks to students as retards, or to demand the printing of one copy of the best free book on the subject, for 1/10 of the cost.
How will you make money?
Nothing changes really. Minireference continues to sell university-level textbooks; we just make the high school material and the toolchain free. As for the potential loss of business due to high schools printing on their own instead of buying textbooks from me, I’d call that a win overall.


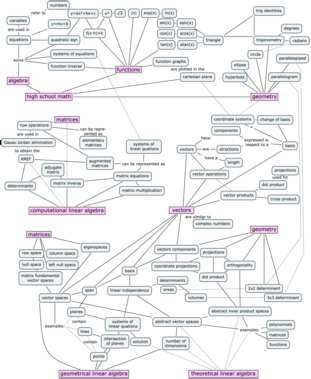
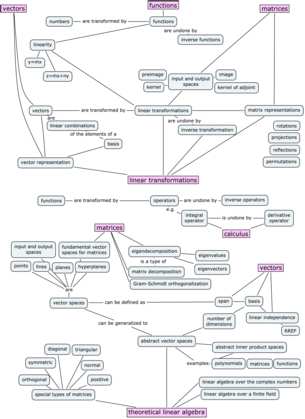
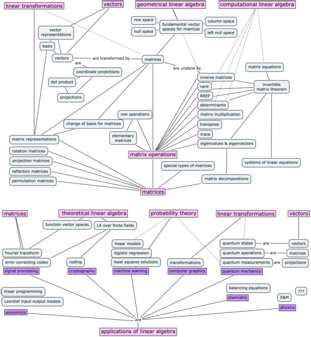
{kind=link}
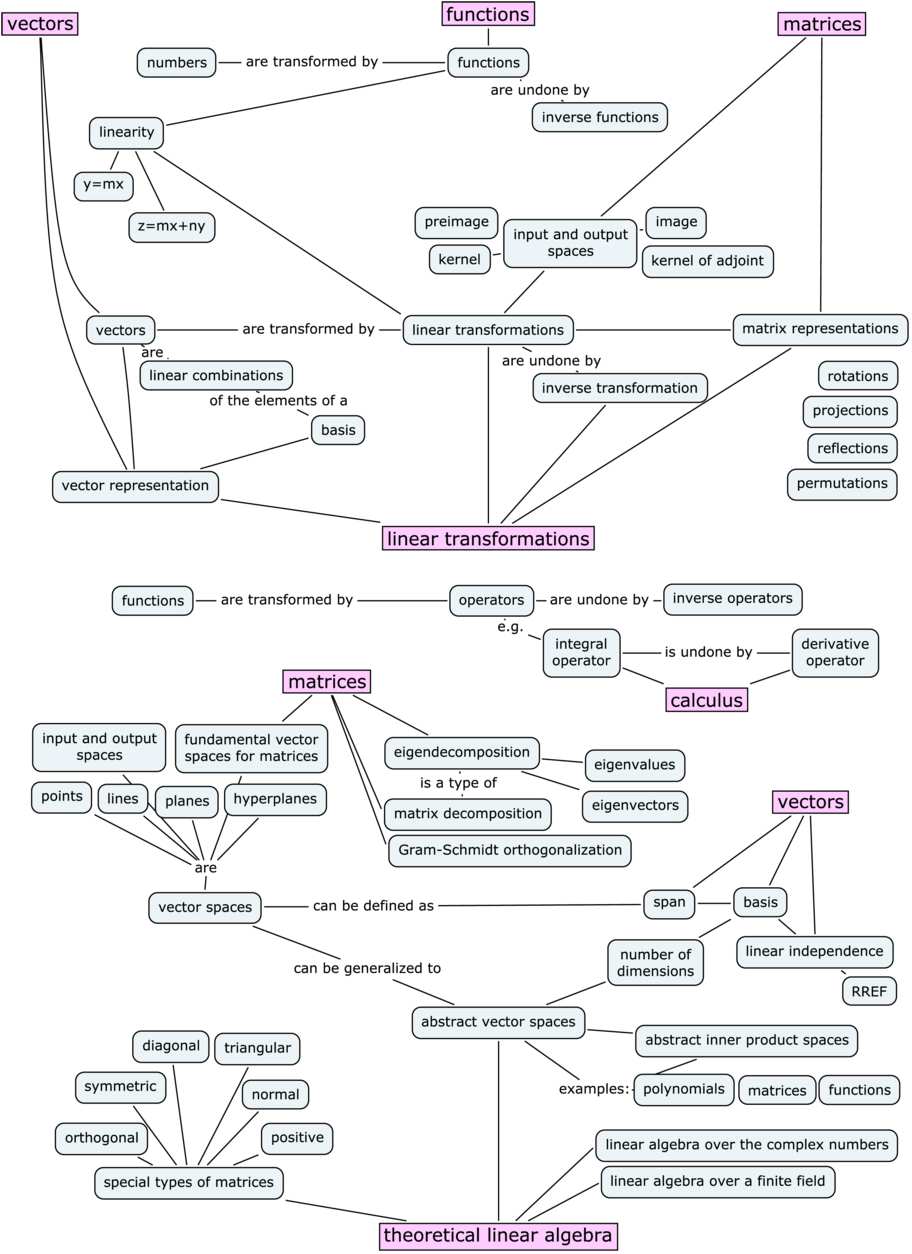{kind=link}
{kind=link}