I want to tell you about my journey to produce the ePub files for the No Bullshit Guide textbooks. This has been an epic battle with lots of technological obstacles, but I got it working in the end, and the results are beautiful:
In this blog post, I want to share what I’ve learned about generating ePub and Mobi files from LaTeX source files that contain lots of math equations. I feel this ought to be recorded somewhere for the benefit of other STEM authors and publishers who have LaTeX manuscripts and want to convert them to .epub and .mobi formats. Read on to watch the “How it’s made” episode about math eBooks.
The end-to-end book production pipeline looks like this:
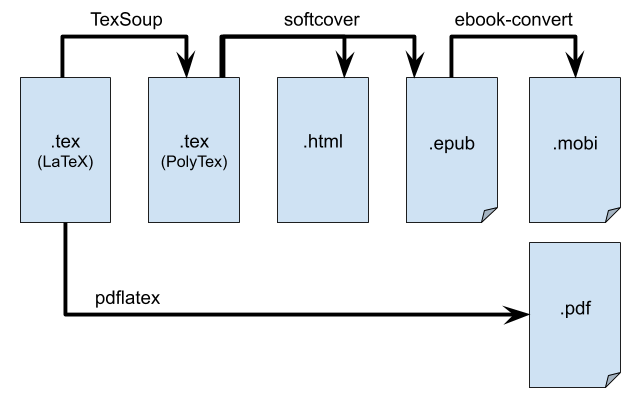
Figure 1: The eBook production pipeline described in this blog post. Each box represents a different markup format and the arrows indicate the software used to convert between formats. The hard step is to produce clean .html+MathJax format from the .tex source. The generation of the other formats is standard.
Historically, the primary tool I used to produce the No Bullshit Guide textbooks has always been the pdflatex, which is the most common way to produce PDFs in the LaTeX ecosystem. The problem is the fixed-width layouts of PDF files are not a good fit for mobile screens and eReader devices with varying screen sizes. Modern publishing is all about reflowable formats like HTML and ePub. If we want more people to learn math, we have to make math textbooks readable on mobile.
The solution for ePub production that I came up with looks like this:
- Transform the LaTeX source files to the macros supported by Softcover (using Python scripts for TeX wrangling based on TexSoup, and image conversion using ImageMagic)
- Convert the LaTeX to HTML+MathJax equations (performed using softcover, polytexnic, and Tralics)
- Generate an ePub file from the HTML (orchestrated by softcover based on MathJax, PhantomJS, Inkscape)
- (bonus) Convert the ePub to Mobi (thanks to ebook-convert command line utility that comes with Calibre)
The conversion process is fairly complex and depends on tools written in several programming languages. Seriously, there are like 6+ different programming languages used in this pipeline: Python 3.x, Python 2.7 (because one library needs it), Perl, Ruby, JavaScript, and Bash. If this were a collect-them-all contest, I’d be winning big time! It’s a lot of dependencies to take on at once, but it had to be done. Besides, the Rube Goldberg machine is a well-recognized software design pattern 🙂
I’m super proud of the scripts I created for automating this pipeline, but I want it to be clear the real credit for everything you’re about to read goes to the people who developed the tools that I used. I was standing on the shoulders of giants: Michael Hartl (softcover and polytexnic), Alvin Wan (TexSoup), and Kovid Goyal (calibre). These are the people who made all this possible through the open source software tools they maintain. They deserve the real credit—my contribution is simply to connect these tools to build an end-to-end pipeline using some Python scripts.
Is this blog post for me?
If you only have 10 more seconds of attention left, the only thing you need to know is to go install softcover (install instructions) and use it for any new projects: it’s the best way of converting math books (.tex source files) to .epub and .mobi. Start with the sample book produced with (softcover new --latex mybook) and extend the chapters while compiling regularly.
Sujet divisé
- In the first part of this blog post, we’ll start with some background on eBook file formats. Think of this as the definitions section in a philosophy paper. What is an ePub file? (spoiler: it’s a zip file with .html+metadata in it) We’ll also talk about the software tools that I highly recommend for generating these files: softcover, and Calibre.
- This part should be interesting for anyone in the “eBook business” since understanding the underlying formats—the files that finally gets downloaded on readers’ devices—is a big thing. Even if you’re not technical, you need to know this stuff.
- There will be some technical details (like command line terminal or cmd.exe) but it’s not that bad. In fact the tools described can probably be used by anyone who can get over the OMG-this-is-a-command-line-thing fear. Once you go through the process a couple of times, the “What am I supposed to type here?” moments go away, and you’ll know what to type: commands. Just like point-and-click commands run programs, command-line terminal commands run programs too.
- The second part of the blog post will get into the nitty-gritty details of the transformations and processing steps described in Figure 1. There will be a lot of link-dropping to useful scripts, but note some of the scripts are very specific to the .tex macros used in the No Bullshit Guide textbooks, so don’t expect to reuse the same code directly. Think of it more like sample code. Or badge:proof-of-concept.
- The technical details will only make sense after you have researched Softcover and Calibre, you’ve played around with them, and now you want to learn how to use them glue them together using a script. This code walkthrough is mainly written as a remember and how-it-works logbook for the Minireference Co. dev team (yours truly).
- The technical parts will be interesting for anyone who needs to convert equation-heavy .tex books into .epub files, and insists on the math equations not looking horrible. Basically, if you’re a self-respecting self-publisher of math textbooks, then we’ve got some scripts for you!
Let’s begin.
Nouns: eBook File formats
Let’s talk a little bit about eBook formats before we get into the technical details. It’s good to know a little bit about the final products we’re trying to produce.
Kindle file formats
The Kindle file formats (.awz, .awz3, .kf8, etc.) are a family of proprietary format used on Amazon Kindle devices. There is no way to generate Kindle eBooks directly, instead, the recommended procedure for KDP distribution is to generate an ePub file and let KDP take care of the conversion to their proprietary formats. So for distribution on Kindle devices through KDP, the key is to generate a good quality, standards-compliant ePub.
Mobi format
The .mobi format (short for Mobipocket) is another proprietary eBook file format that was very popular before the wide adoption of ePub. Early versions of the Amazon Kindle used mobi format internally, so the mobi format is still supported on Kindle devices.
It’s considered good practice for eBook publishers to offer .mobi files in addition to .epub for the benefit of readers who have a Kindle device, since Kindle devices don’t support ePub files natively. Luckily there is an excellent command-line tool for this (ebook-convert) that comes with every installation of Calibre.
Using ebook-convert is really simple. If you have a source file book.epub, and you want to convert it to .mobi format, you can run
ebook-convert book.epub book.mobi --mobi-file-type both
and you’ll end up with a file that is readable by all Kindle devices.
ePub format
This is the most widely-supported format for ebooks and the main focus of our efforts here. The ePub file format is based on web technologies like HTML and CSS, and it is codified as an IDPF standard. An .epub eBook is a self-contained container of HTML, CSS, images, and metadata that is packaged as a .zip file. If you have an ePub file you can change it’s extension from .epub to .zip and unzip it to look at the contents. You can also use an ePub editor like Sigil that lets you “view source” and modify ePub files directly without the need to unzip them first.
The use of HTML for content is—in principle—a good thing. In practice, different readers have different levels of support for markup, styling, and media playback, and very few ePub readers support the possibility of running scripts. For this reason, we take a conservative approach and target the basic ePub v3 format, without taking advantage of modern features of the web platform like SVG images, audio playback, and interactive elements. I’m looking forward to exploring these advanced features of ePub3 in the future, but for maximum compatibility, I will avoid such niceties for now and assume the “client” is a bare-bones eReader device that only supports basic HTML, CSS, and images.
So how do you build an ePub? Theoretically you just prepare your book using HTML markup and you’re done. Well, not quite. When I said the ePub format is based on web technologies like HTML and CSS, it’s a bit misleading, since that covers only the content pages—the chapters of the book. Additionally, a standards-compliant .epub file must also specify the book metadata (content.opf) and structure (toc.ncx). There are several “ebook frameworks” like pandoc, Sphinx, gitbook, etc. that can be used to produce ePubs. If your book doesn’t contain math equations, I would recommend one of these well-established frameworks to “outsource” the complexity of generating the ePub. See this blog post for example.
However, in the case of the No Bullshit Guide textbooks, we’re starting with 1000+ pages of LaTeX source files containing A LOT of equations.
Statement of the problem: Generate a good-looking ePub file from LaTeX source files that include equations, figures, tables, and custom macros for exercises and problems.
The occurrence of the word “custom” should give you a hint that things will get interesting soon…
Verbs: Software Tools
Let’s now talk about the software tools that perform the specific transformation from .tex source to .epub file. In order of importance these tools are softcover, calibre, TexSoup, and fab-classic. We start with the most important parts first: the tools that are broadly reusable in any context; we defer the technical details about the specific transformations we perform until the second half of this blog post.
Softcover and PolyTexnic
Enter the first protagonist, the softcover project. Softcover is a framework for producing eBooks from markdown or LaTeX source files. You run a single command (softcover build) to build all kinds of book formats including PDF, ePub, and Mobi. It is a beautiful thing written in Ruby.
As soon as I learned about this project I knew it was the way forward. I had previously tried several other tools for generating ePub files form LaTeX, which worked well for short articles and blog posts, but failed on longer texts like the No Bullshit Guide textbooks. All the other approaches I tried before softcover were inferior in one way or another, and none of them supported all the markup needed for the No Bullshit Guide textbooks. Softcover supports 90% of the markup I need straight out of the box, and missing pieces can easily be added.
So softcover is good, however there was one big problem: the fact that I don’t know anything about the Ruby ecosystem. What is a gem? What is a bundle? What am-I supposed to rake exactly? It’s not an easy feeling being the “clueless beginner” and it reminded me of the early days when I was learning to code and couldn’t even get the basic dev setup working, let along program anything. But softcover is so good, that—prior Ruby knowledge or not—I knew this was the tool for the job.
Restatement of the problem: learn enough Ruby to use softcover and customize the code to support LaTeX macros used in the books for figures, exercises, and problems.
The way softcover works internally is based on a (subset of) LaTeX source file format called PolyTex, which gets processed to produce HTML files and from there ePubs. The softcover LaTeX format (PolyTex) includes 90% of LaTeX macros I use in the books (inline math, displayed equations, figures, tables, references, etc.), all I have to do is pre-process the book source files to make them softcover-compatible. Sounds simple, right?
TeX manipulations using TexSoup
Enter the second protagonist in this story: the LaTeX processing library called TexSoup created by Alvin Wan. The name TexSoup is an analogy to the popular library for processing HTML markup called BeautifulSoup. In case you’re wondering about the etymology, the term “soup” refers to the messy markup of most web pages, which is usually a jumbled soup of tags that are difficult to parse by hand and require a soup-parsing library to help with this task.
I had previously attempted to make the books’ source files softcover-compatible several times using ad-hoc sciripts based on sed, python regular expressions, manual annotations, patches, Perl cleanup scripts, and several other hacky solutions. None of these prior attempts worked well, since parsing LaTeX with regexes is inherently a lost battle.
In contrast, the TexSoup library is capable of parsing LaTeX source files “logically” and allows for rich tex manipulations similar to what BeautifulSoup allows for HTML. You can find particular elements using find and find_all methods, and make content manipulations programmatically using a civilized API. What more can one ask for than a Python library that does exactly what you need to do!
When I discovered the TexSoup library, I immediately recognized it as the right tool for the task of transforming the book source files to softcover-compatible format. The combination of TexSoup for transformations and Softcover for generating eBooks is the right way to do this. All I had to do is write some scripts to combine these two tools.
Automation for the win
There is an unspoken strategic objective that motivates this entire effort. I want the eBook production pipeline to be fully automated: from .tex to .epub in one command. Having an automated pipeline is essential to support the process of continuous improvement (Kaizen textbooks) which is a central ethos of the Minirefrence Publishing Co. All the books are continuously updated based on readers’ feedback: typo fixes, polishing rough explanations, adding links to external learning resources, etc. If producing ePub from the source files required any time-consuming manual steps, then the ePub files will be second-class citizens, since they will not be updated regularly like the print books, which is something we want to avoid.
The tool I used to automate the process of .tex soruce transformations and subsequent eBook generation is called Fabric (specifically fab-classic which is a fork of the Fabric project that maintains backward compatibility with the original API). Any other automation library could be used to achive the same results, but I chose Fabric because I have the most experience with this zero-magic Python scripting framework. If you know what a Makefile is, then you’ll easily recognize how fabfile.py works.
So this is where I was on October 12: I had the tools ready and the plan figured out, but I still needed to do the work…
In the remainder of the blog post, we’ll give some more technical details about TexSoup Softcover automation scripts for transforming LaTeX source files to ePub. My goal is to write a complete “walkthrough” for the code in the sample-book repository.
¡Vamonos!
Source transformations
The term “data pipeline” is a fancy way to talk about a sequence of transformations you apply to some data: take this input format, transform it to another format, then output a third format. In this case, the pipeline takes LaTeX source files as inputs, transforms the LaTeX to XML, then does some further transformations to finally output the HTML files that get packaged into an ePub file. In the earlier parts of the blog post we introduced the nouns (file formats) and the verbs (software), now it’s time to put together a whole sentence.
Transformation 1: LaTeX to PolyTeX
The first step of the pipeline requires processing all the LaTeX macros and styles used in the Minireference books (see the tex header file), and transforming them to the softcover-compatible PolyTex format.
LaTeX source format
The No Bullshit Guide textbooks are mostly written in “standard” LaTeX. There is a common header file called 00.minirefrence.hdr.tex that defines the page setup, font selection, and a few custom macros like \eqdef for ≝ (read “is defined as”) and \sfT for the matrix transpose symbol.
The Minireference header file also defines some custom environments for the exercises and problems sets in the book, which are stored in separate files that get included in appropriate locations of the main text. Each problem consists of a question, an answer, and a solution. These three parts get treated differently: the question appears in the main text, while answers and solutions are sent to special files (e.g. answers_ch1.tex and solutions_ch1.tex respectively). These files get included in the Answers and Solutions appendix. The answers LaTeX package and these custom macros enable this.
The figures in the book consist of a mixture of concept maps, charts, plots, force diagrams, and other illustrations. As part of previous updates to the books (2019), I did a lot of work to replace my ugly hand-drawn diagrams with beautiful vector graphics generated with TikZ (many thanks to Robyn Theissen-Bock who led this effort). Each of these figures is created from a separate .tex source file based on the standalone document class, and each time you build the pdf version of a figure, a .png file with the same name is also generated (this will become important later on).
Overall the books are pretty much “vanilla” LaTeX with very few macros and customizations. That’s the whole point of LaTeX: the basic book documentclass is so powerful that you don’t need to do anything custom to produce beautifully typeset books.
PolyTeX target format
The subset of the LaTeX syntax that is supported by the Softcover framework is called PolyTeX. PolyTeX covers 90% of the macros used in the No Bullshit Guide textbooks, so right out of the box, tex-compiling the books source files with Softcover gives a pretty decent result.
However 90% is not 100% and we have to do some transformations to the source files to make them work. The specific things I had to do to get to 100% are:
- math macros (custom math shortcuts and environments I have defined)
- problems and exercises (custom rules for skipping answers and solutions in main text implemented in Ruby).
- chapter and section files: softcover expects the book’s chapters to be presented as entire files, which is not directly compatible with the approach of splitting each section in it’s own source file I use for the books. I therefore had to concatenate the source files of individual sections to create chapter files.
- figures: due to a quirk in the way the underlying tool Tralics operates, every figure’s
\labelmust be placed inside a the figures’s\captionin order for references to work right. No problem, this is a five-liner in TexSoup. - tables: parsing table is a challenge for any markup platform and this was no exception. In the end I wrote a set of ad-hoc transformations for specific tables in the book.
It took me about a week and a half of intense coding to put together all these conversion procedures required to transform No Bullshit Guide LaTeX to softcover-compatible PolyTeX.
ETL = Extract Transform Load
The concept of an “ETL job” is a standard jargon term in the enterprise world, referring to the process of “ingesting” (extracting) data from an external system and “injecting” it into your company’s system (loading). The source data is rarely in the format expected by your internal systems, hence the need for the transformation step in the middle.
Extract-transform-load pipelines are a useful design pattern to manage the complexity of dealing with data in general. First you extract the source data in whatever format you can get, then you do one or more transformations, and finally you output the format expected for further processing. Here are the four steps of the pipeline I created:
- Generate a source manifest: this step starts with the book’s “main” file and recursively follows all included source files to create an exhaustive list of the files needed to build the book. The results is a YAML manifest file that can be inspected and manually tweaked.
- Extract content: the source manifest tells us all the files we need to extract from the book’s external source directory to a new temporary directory (sources/extracted/). This is a fairly straightforward step that just copies the files listed in the manifest without doing any processing on them. The purpose of this step is to make sure we don’t mess up the source files (decouple the ePub generation from the book’s source files). To check this step worked, I compiled the extracted files to generate a PDF with matching page numbers, which reassured me the info in the manifest is complete and all the necessary files are being extracted.
- Transform content: this consists of all the .tex source transformations needed to convert the LaTeX source files to the PolyTeX format expected by Softcover. The transformations include: changing the structure of figure captions, simplifying tables markup, and a bunch of ad-hoc “cleanup” steps that I had previously developed using a lot of trial and error.
As mentioned above, the figures in the book are available in both .pdf and .png versions: this greatly simplifies the transformation step since the PNG figures are already available to include in the ePub. Still, some graphics like the concept maps that are only available in PDF format are transformed to ePub-compatible image formats at this stage. The resulting transformed source files and images are placed in another temporary directory (sources/transformed/). - Load content: the loading step takes the files in the sources/transformed/ dir and puts them in the appropriate places where softcover expects to find them (chapters/, images/figures/ instead of figures/). This step also generates the book’s main file, which specifies the top-level includes for the chapters in the book.
That’s it. Half the work is already done—we just have to handoff to Softcover for the rest!
Transformation 2: PolyTeX to HTML
This transformation is all taken care of by the softcover framework, which is based on the polytexnic library, which in turn uses the Tralics LaTeX-to-XML converter. The softcover pipeline for producing HTML looks like this:

Figure 2: The internal transformation steps used by Softcover.
Typical users of the softcover framework don’t need to understand all the inner workings. I’m writing about this only because I think it’s a marvelous feat of engineering. Big up Michael Hartl for inventing this!
The steps of this transformation are:
- Preprocessing: a PolyTex source is annotated with additional LaTeX commands like references and reference anchors. All math environments that we don’t want to process with Tralics get swapped out.
- Tralics run: converts the LaTeX to XML. I haven’t looked much at how it works, but I noticed it is a very robust program—it rarely chokes.
- Postprocessing: the XML output produced by Tralics is then massaged into standards-compliant HTML form, and the equations are swapped back into place (to be rendered by MathJax later on).
The results of Transformation 2 is a set of files in HTML+MathJax format that can be opened in any browser.
Transformation 3: HTML to ePub
The HTML+MathJax format we obtained in the previous section is not suitable for use inside an ePub because it requires JavaScript to render the math equations. The workaround for this is to pre-render all the math equations as images. This sounds simple in theory, but is quite a complicated process in practice. The following quote summarizes the process very well:
The real challenge is producing EPUB and MOBI output. The trick is to (1) create a self-contained HTML page with embedded math, (2) include the amazing MathJax JavaScript library, configured to render math as SVG images, (3) hit the page with the headless PhantomJS browser to force MathJax to render the math (including any equation numbers) as SVGs, (4) extract self-contained SVGs from the rendered pages, and (5) use Inkscape to convert the SVGs to PNGs for inclusion in EPUB and MOBI books. Easy, right? In fact, no—it was excruciating and required excessive amounts of profanity to achieve. But it’s done, so ha. — Michael Hartl
It’s almost a pipeline within a pipeline! The steps described are all carefully chosen for a reason:
- (1) The single-page HTML for the whole book is required so all the references and counters will work correctly. This would not be possible if each chapter was rendered separately.
- (2) Using MathJax SVG render is not the default (usually the HTML render is better), but we need an SVG for step (4) to work.
- (3) Rendering the whole book with PhantomJS takes a few seconds, and by the end of it we have SVG code for each equation available in the page DOM.
- (4) Next we parse the rendered page, locate all the SVG math images and prepare to replace them with the equivalent PNG images.
- (5) The SVG-to-PNG conversion is done using Inkscape as a separate command line invocation, and finally the whole thing (HTML + PNG math images + book metadata) gets written inside the final ePub file.
Some of the more tricky things associated with the process involved “smart” vertical placement of inline math equations so the math font baseline matches the surrounding text font, choosing the right resolution for the SVG-to-PNG conversion (too small and math looks pixelated, too large and ePub files end up being 20MB+), and some accessibility considerations to make sure math images contain the LaTeX source as alt tags. It’s a pretty crazy little pipeline, but it works!
Conclusion
I hope this blog post has been useful for people who are looking for ways to convert their math books from LaTeX to ePub. It’s not a simple process by any means, but we have to work on it so that math can be a first-class citizen in the new digital books economy. Seeing math equations as ugly images in ePubs published by big publishers made me very sad and discouraged—if big-name publishers can’t make decent-looking math ePubs, then what chance do I have?
This is why I’m so happy to have discovered this “civilized” way of producing .epub/.mobi from .tex files and why I wrote this long wall of text to share the info with y’all. There is a bigger lesson to learn here: never despair—sometimes an independent publisher with a team of one can end up ahead of the curve in eBook production technology. With access to FOSS (free and open source software) tools and libraries anything is possible!
Speaking of open source… the toolchain I build is very specific to my use cases, but I’m still open sourcing the sample-book repo where all these scripts were developed in case other authors want to follow in my footsteps for their LaTeX to ePub conversion needs. This is the power of community and sharing. Even complicated tasks can be tackled when we work as a group, and people from around the world can collaborate around these projects for their personal motivations and incentives. We’re literally building printing presses. That’s a beautiful thing.
Product links
For readers wondering “Where do I get them math books?” right now, here is a list of the different options:
- If you’ve already bought the book(s) from Gumroad, there is no need to buy anything new—the new ePub and Mobi files have been added alongside the PDF version. You can download the files through the Gumroad link you received when you purchased the book. Look for an email with subject “You bought …”).
- If you have bought a print book of any of the books, then you can send me a proof of purchase of some sort (e.g. picture of the book or FWD of receipt email) to combodeal@minireference.com and and I’ll hook you up with the latest .epub and .mobi of your book.
- For new readers, here are the links to where you can get the books, in both digital and print formats.
- The No Bullshit Guide to Math and Physics (high school math review, mechanics, and calculus) is available in print from lulu[softcover,hardcover] and amazon[softcover], or digital download [gumroad] (PDF, ePub, Mobi).
- The No Bullshit Guide to Linear Algebra (concise high school math review, linear algebra theory, linear algebra applications) is available in print from lulu[softcover,hardcover] and amazon[softcover], or digital download [gumroad] (PDF, ePub, Mobi).
- Last but not least, the No Bullshit Guide to Mathematics is a short book that contains just the high school math review sections, and specially designed for adult learners who want to overcome their math anxiety problem. As an adult, you can (re)learn math fundamentals much more easily then when you were in school. Get you math phobia therapy in digital form via Kindle or via Gumroad, or in print from lulu[softcover,hardcover] and amazon[softcover].
Kenneth L Kuttler
October 6, 2021 — 2:33 pm
It doesn’t tell me how to do it. I need command line instructions to accomplish it, something like htlatex file “mathml”. It doesn’t help to see pretty flow charts.
ivan
October 7, 2021 — 9:42 am
Good point. The best thing would be to try regular softcover, since this is the really powerful stuff:
See here for more info https://manual.softcover.io/book/getting_started#sec-installing_softcover (you’ll need to install some additional software like Calibre and ePubCheck to have a full working system).
As for my scripts, these should be relatively less interesting since they are very specific to the LaTeX syntax I use in the books. You can look at the processing steps more as examples than reusable functions… Still, if you want to see the whole pipeline of transformations, you can do this using:
Mark
October 25, 2021 — 7:37 am
Cool tool, but why not just use pandoc? It can convert between various formats, including latex and epub.
ivan
October 25, 2021 — 10:33 am
The key special need in my case is to support math equations (and I’ve got LOTS of them). Pandoc is great when converting LaTeX to HTML that will be viewed in the browser since the math then works with MathJax, but when generating ePub you need to somehow convert the equations to images, and this is difficult to do right. In my experience,
softcoveris the best tool for this job, hence I wrote all the scripts and “adapters” described in the blog post to make sure I can use softcover/polytexnic.Steven Obua
December 28, 2021 — 12:53 pm
Interesting stuff. I checked out the generated epub, but the equations are still looking too pixelated. I’d consider either cranking up the quality of the SVG to PNG conversion; 20MB+ doesn’t sound too bad, I would be more concerned about the viewing quality than the size. Alternatively, couldn’t the SVG’s be included as is, without conversion?
ivan
December 28, 2021 — 9:33 pm
Hi Steven, thanks for your comments. You give me at least two ideas to experiment with.
Yes, the default softcover resolution is too coarse and pixelated. In my custom builds I used this, which is better but still not the as good as it should be (ideally one should use 2x resolution of intended display on old devices, so the math will also look good on newer high-DPI eBook readers)
If you’re interested in testing a few “builds” you can reach out to me by email (first name at domain name) and I can send you some samples.
Theoretically SVG should be supported in newer ePub3-compatible eReaders, but practically the support is very hit and miss. I should still do a test build and see which readers support it though—it would be so much cleaner to have vector graphics in there! The PNG route still needs to be supported for .mobi format and in general anything that goes on Kindle.
I’m thinking there could be some command line switches to softcover to enable high-res PNG mode, and an experimental SVG mode for ePub.