Earlier this year I launched my book on hacker news which resonated very positively with the hacker crowd. This HN exposure landed me an interview on the TechZing podcast to discussed my textbook project. Even though it was an hour and a half long interview, there were a some things that we didn’t get to discuss. I want to take the moment now to write down my observations about the textbook business and the educational market.
This blog post is organized with the best stuff at the top so feel free to trail off at any point.
Insights
The most important things I’ve learned about the textbook business:
- Writing is tough, but writing down lecture notes after a lecture is easy.
- Teaching students is gold. By interacting with your students 1-on-1 you get feedback on your explanations.
If you are lucky you will get a “Sorry, I didn’t get that”, which allows you to iterate.
- People still appreciate the printed book. Some people are willing to pay good money for a PDF.
Opportunities
Print-on-demand and eBook technology allow for everyone to publish and sell books. This is a revolution on a Gutenberg scale. One of the forefathers of the Internet/WWW, when asked about the motivation behind his inventions said he did it “so people will be able to earn a living from the fruits of their intellectual labour.” We have now finally reached this moment where this idea is practical. Could books be the missing monetization strategy for the Internet?
What have been traditionally two markets—the general audience and the educational market—are now becoming a single market of people who want to learn. Lord knows there are things to learn out there so there is an opportunity for knowledge products for people who want to learn. The key monetization routes will be through selling organized knowledge as textbooks, ebooks, or apps.
I used the term revolution above and I stand by this choice of wording because this is what we call it when a value chain collapses from six-plus levels to three levels. The value chain in the “book business” previously looked like this:
author
__editor
__copy-editor
__typesetter
__printer
__distributor[1..]
__book store
__client
With print-on-demand the new book business will look like this:
author -- printer -- shipping -- client
^^^^^^ ^^^^^^
Let us call this “author centered” publishing. From now on, authors can expect to get up to 50% of the profits instead of 10% (which could be as low as 5% of the list price). Good times for authors. Incentive-giving-to-move-to-a-new-publisher times.
Even amazon looks like a dinosaur in this context:
author
__editor
__copy-editor
__typesetter
__printer
__amazon
__shipping
__client
Why do you need the warehouse to store all the books? Why not ship from the printer?
There is one element in the traditional publishing value chain that we must keep. Copy editing is actually very important because you really want someone to go through
your writing and fix mistakes in it. You can use your target audience (crowdsource copy-editing), but nothing beats professional services.
OK, so you want to see the future of publishing? Here it is:
author -- (1) pub.srvc. -- (2) printer -- shipping -- client
_ (3) booksite -- client
The opportunities are (1) for small publishing houses (copy editor + creative person for covers + latex guy) to really come-in and take over the entire market within a couple of years. You could also have larger publishers who focus on marketing the book to certain audiences etc.
Opportunity (2) is for new print-on-demand shoppes to come up (compete with lulu.com and lightning source). These giants have as their main advantage the established processes they have in place, but how difficult would it be to build an “Espresso Book Machine”-like system based on a quality BW laser printer (think buying toner in gallon tubes at costco 😉 and some automation. The competitive advantage of a small print shop would be that they offer pick up service (0\$ shipping). Currently lulu charges you 6\$ for shipping to Canada (9\$ for 2 books, 12\$ for three books, …, 3+3n.) Shipping within the states is \$5 which is better, but still not free. In particular for printing small books (100-200pp) it would not make sense to order from lulu. They would charge you 5\$ for the printing and another 6\$ for the shipping. Your cost 11\$. If you go to a local print shoppe, they will charge you 7\$ for printing. Same product, half price.
The third opportunity is for high-level editorial services (think curation of content) which would collect book recommendations and let authors and readers interact. Ideally there should be independent “book blogs” for discovery of new content — not marketplaces. Something must be done about the current appstore monopoly. Every app you develop relying on Apple for your distribution is feeding the monster at 30%. Every web app you develop based on Google or FB apis could stop working tomorrow if the API is retired. Go get hosting somewhere and build your own website. Don’t depend on anyone. Okay sorry I got a little off the topic of textbooks. Let’s get back on topic.
I was telling you guys about the book and stuff from the interview. One thing which we talked a lot about was the hacker news launch.
The HN launch
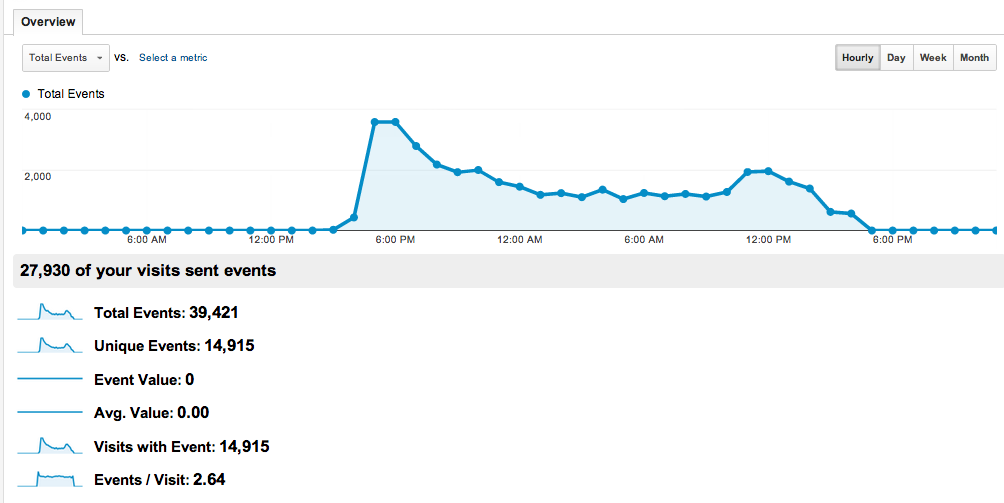
I told Jason how surprized I was when I got 30 000 visitors in one day and how I didn’t get up from my chair for one day. There were roughly 7000 people who clicked on one of the modals. Of these 300 people bought the book in print. By the evening of Jan 1st and into Jan 2nd there were also 100 PDFs purchased from gumroad.
I still working out the numbers (conversion rates) and I don’t want to get too hyped up about them (ok ok, 7k –> 300 = 4.3%) because the HN audience is really VERY sympathetic to the product. I am not sure if everyone else on the internet will like it as much.
(SIDENOTE: I am finding it hard to get the analytics I want for the book page. GA reports analytic en masse so I cannot see what individual visitors did when they came to the site. I have basic questions I need answers for and it seems like the current state of analytics is very unimpressive (relative to my expectations). Here is what I would like to know:
- Which modal my visitors looked at before deciding to continue onto lulu.com/shop or gumroad?
- Which of the 800 people who clicked through to lulu.com/shop are the 300 that actually ended up buying the book?
- Which sections did they read (scroll to and stay for 4secs+)?
- What “path” did each visitor follow through the modals? (subquestion: did anyone see the apg-get install mechanics? did anyone see the integral calculus modal? )
Are there solutions for these? I think the only way I can have end-to-end information is if I run the whole show. If I want to have information about converstions I must build my own shopping cart. Wait, we are on the Internet — I can just submit a feature request to lulu.com support and gumroad support. I am working on the full writeup of the launch experience here which will have more graphs and numbers. (/SIDENOTE)
I got a lot of feedback from the discussion on hacker news. People really like the idea. The tech crowd of Hacker News is precisely the kind of crowd is interested in learning about advanced math and physics. Many programmers learn the about calculus in mechanics at University but never actually understood these subjects. This is way when the no bullshit guide to mass in physics the really wanted and the 29 dollars price range is definitely not an obstacle for them. Several people also asked for a PG 13 version cleaned up with out of cities in the references to park and alcohol. This is definitely something I will look into it because no told jokes need to be about these subjects. We can stick to the political stuff and the joke about the investment banker being dropped off a building.
What is the goal of the book?
The goal of the book and more generally of Minireference Co. is to teach. Teach students how to get rid of the exam stress when they’re doing their studies. If you know the material really well, then there is nothing tricky that the teacher
can do on the final. Understanding trumps memorization any day of the week. A secondary goal is to teach math to adults, grown ups, so they can let go of their math complexes. There is no reason why a forty year old person should avoid conversations about math and feel uncomfortable when their teenage daughter or son asks them about the solutions to a quadratic equation.
The third goal is to prevent the next generation of analytic reminded youth from going into the defence, pharmaceutical and finance sectors, which I consider to be detrimental to society. I grew up listening to Rage Against the Machine and I feel it is my duty to continue their work in educating the next generations about the system. By situating analytical knowledge in the context of the current world geopolitical situation, it is my hope that the next generation of Einsteins, Gates, Pages, and Zuckerbergs will make informed and moral choices. With knowledge comes responsibility, and I don’t want my students to think about the numbers without understanding what the numbers represent in the real world.
Textbook market
There are a couple of intrenched companies in the publishing world (the big five). Mainstream publishers in the educational market produce textbook that are so expensive, that we can talk about a textbook racket. The readers, subject to their teachers authority, are forced to buy specific textbooks, often at an exorbitant prices > \$100. Mainstream textbooks are also too long and full of fluff like full-page photos designed to pad the pages and impress the student with the “high endness” of the 1000-page publication. Mainstream textbooks are the kind of product which is the signed by committee. They’re thick and boring.
On the other hand there are several positive things about textbooks. Irrespective of the widened usage of electronic formats, the “book format” remains the primary medium of intellectual discourse, of which textbooks are a subset. Textbooks are old technology, but good technology. Textbook, as a mean for acquiring knowledge, are better than most educational resources produced for the web. And it’s not just eBooks, print is here to stay because students don’t like the idea of ebooks replacing textbooks. Having a PDF to go along with your printed textbook is definitely a feature, but not as a replacement.
Business model
The business model for Minireference Publishing Co. is quite simple: we sell math and science textbooks and PDFs. The specifics of the book “container” are not important. What is important and of value is that we offer an “information distillation” service: complicated science subjects are presented and explained in a concise coherent narrative, including all prerequisites. Instead of reading 100 wikipedia pages to learn about calculus in a month, students can read one chapter in the No BS guide and pick up the same material in a week.
Backstory
During the interview, I had a chance to give the full story about the genesis of the book. At 7min40sec in the interview, I say how I started from a collection of notes on advanced physics subjects and that at some point decided to make those notes into a book. Jason replies to this jokingly “Wow that is a big jump!” but I totally missed his joke and just kept on blabbing.
Pivot 1: TOO ADVANCED. There are not that many physicists. We need to go for something more mainstream. New product will be a mini-reference book of formulas for all of science.
Pivot 2: FORMULAS ARE NOT ENOUGH to learn. Let’s have the formulas, but add enough context and explanations to explain where the formulas come from and how they are used.
Once you have the idea… It took two years and 200 commits. It wasn’t high intensity work: I just wrote down lecture notes and my favourite explanations after teaching. During the summer of 2012, I worked intensely to tie together and organize all the material into a coherent story with a beginning (solving equations), a middle (use equations to predict the motion of objects in physics), and an end (learn where the equations of physics arise from calculus).
Product
What is special about this book is the deed forms contains a complete dependency graph of topics. Each subject is explain along with all the prerequisite material.
Another thing special about the book is its conversational tone. The narration in the book switches from serious to joke mode and back to serious again, and is intended to keep the reader engaged. Everyone needs a little brake after learning pages and pages of formulas…
Technology used
During the interview, I didn’t get a chance to discuss the technology stack I used to generate the book. The book started as a bunch of text file in dokuwiki. I then used the dokutexit plugin to export the book as LaTeX.
Another important tool for the production of the book has been to use the text-to-speech tool in Mac OS X for proofreading. It allowed me to catch lots of mistakes and quickly.
I use lulu.com for print-on-demand and gumroad.com for the PDF distribution.
Future
Some future directions for the development of the book are:
- Finish the linear algebra textbook
- Write Tome II on electricity and magnetism and vectors calculus
- Future plans: Write a book about probability and stats
- Future plans: Make a No BS guide to Python and JavaScript
Speaking of JavaScript I’m currently exploring the using khan-exercises framework so I could offer practice problems on the site.
The main challenges we face right now is marketing the book to a wide audience.
UPDATE: Since the publication of this post, the No Bullshit guide to math and physics has been improved and revised several times. Sales going Okay. Need more word of mouth…






{kind=link}