It’s May. Winter is done now, so it’s time for spring cleaning! In addition to cleaning your living space, Spring is also a good time to clean out the “project plans” and focus on one or two key goals for the summer. This is what I intend to do in this post. Read on to learn about the recent developments, and the strategic plan for Minireference Co. for the coming year.
Annual general update
Git for authors
Using version control is very useful for storing text documents like papers and books. It’s amazing how easy it is to track changes to documents, and communicate these changes with other authors. In my career as a researcher, I’ve had the chance to initiate many colleagues to the use of mercurial and git for storing paper manuscripts. Also, when working on my math books, I’ve had the fortune to work with an editor who understands version control and performed her edits directly to the books’ source repo. This blog post is a brainstorming session on the what a git user interface specific to author’s needs could look like.
Linear algebra book alpha release
The No bullshit guide to linear algebra is almost finished. I know I have been saying something along these lines for almost two years now, but it’s for real this time. Read below for a general preview of the new chapters, and the story about why it took so long to write them.
Progress on linear algebra
It has been almost a year now since the linear algebra book is “almost finished.” I don’t have any real, legitimate excuse for this delay. The first seven chapters are now done, and have been thoroughly edited and finalized. What is taking forever is finishing the applications chapters, which I’m being super slow at. The only thing I can say in my defense is that there are A LOT of applications of linear algebra, and writing about even a small part of them takes a lot of time.
Okay, so what’s coming?
- The applications chapter covers topics in cryptography, error correcting codes, network coding, Fourier analysis, as well as the standard topics of least-squares fitting and solving equations.
- I’ve decided to cut the section on linear programming (the simplex method). Despite trying very hard to make the material interesting and concise, I wasn’t able to. It’s just a boring-as-hell topic, so I don’t see the point of including it in the book. The text is almost done though, so I’ll probably release it as a free PDF for students who have to do this in their class.
- I added a new chapter on probability theory, Markov chains, and quantum mechanics. This will be optional reading, but I think I managed to fit all the important things (Dirac notation, postulates of QM, quantum gates, examples, etc.) to make a decent introduction to the subject.
The final version of the book will be around 450 pages, which is kind of chunky. Not cool, but I think it’s good to include the chapter on probability theory and QM, even though they are not “core” for a linear algebra class. What do y’all think? Should I include prob. theory and QM or cut it to make the book shorter by 60 pages (reply in the comments or by email)?
The other good news™ is my friend agreed to prepare exercises and problems for the book, which means the first edition (v1.0) will be very solid and complete. Estimated time of release is circa February 1st. Dear readers, I apologize for the massive delays. Hang in there, LA is coming!
Binary search in three languages
Hola! Regardons ensemble un peu de code. The binary_search algorithm. It will get a little technical, pero no es mucho complicado. A ver. En ingles. En anglais, parce que le code—ça va foule mieux en anglais.
Assume you’re given a array of integers sorted in increasing order [3,6,19,21,87]. You job is to write a “search” function that returns the 0-based index of query value, or -1 if val is not in array.
Binary search algorithm
The “usual” algorithm use the start and finish pointers in a weird way, which I found difficult to understand, so I wrote another one. The invariant “we’ve already checked the limits” feels more logical to me.
In JavaScript
In JavaScript the code for the binary search strategy is as follows:
SearchableArray.prototype.binary_search = function (val) {
var data = this.data;
if (data.length === 0) return -1;
if (data[0] === val) return 0;
if (data[data.length-1] === val) return data.length -1 ;
var bin_search_limits = function(start,finish) {
// invariant: data[start] and data[finish] have been checked already
var mid;
//console.log(start, finish);
if (start === finish || start+1 === finish)
return -1;
mid = start + Math.floor((finish-start)/2);
if (data[mid]===val) {
return mid;
} else if (data[mid] < val) {
return bin_search_limits(mid,finish);
} else if (data[mid] > val) {
return bin_search_limits(start,mid);
}
};
return bin_search_limits(0, data.length-1);
};
The full javascript code (with tests;) is here.
In C
It was surprisingly easy to transform the JavaScript code into C. See the code and some basic tests here. The main functions essentially the same:
int bin_search_limits(int *data, int start, int finish, int val) {
// invariant: data[start] and data[finish] have been checked already
int mid;
if (start == finish || start+1 == finish)
return -1;
mid = start + (finish-start)/2;
if (data[mid]==val) {
return mid;
} else if (data[mid] < val) {
return bin_search_limits(data,mid,finish, val);
} else if (data[mid] > val) {
return bin_search_limits(data,start,mid, val);
}
};
int binary_search(int *data, int length, int val) {
if (length == 0) return -1;
if (data[0] == val) return 0;
if (data[length-1] == val) return length-1;
return bin_search_limits(data,0,length-1, val);
};
In python
The pleasure of implementing binary search in python is left to the reader.
I’ve got to go code learn how to make a hash function to make the C test suite go faster 😉
Linear algebra applications
I spent the last month at the chalet in Petkovo, the village where my grandfather is from. Check out the view from my office:

I have good progress to report on the linear algebra book. Sandy (my editor) has gone through the first few chapters and looks on track to finish editing the book by the end of October, which means the NO BS guide to LA will be available in print soon.
On my side, I’ve been working on the applications chapter. In this chapter I discuss all the cool things you can do using linear algebra. The topics covered include linear programming, error correcting codes, solving for the voltages in electric circuits, and other applications to economics and science. It really feels good to be able to discuss all these applications, and substantiate the claim I make in the book’s introduction, namely, that learning linear algebra will open many doors for the reader.
In other news, I think I’ve finally found a civilized way to generate html and .epub versions of the book: polytexnic, which is part of the softcover platform for self-publishers. Here’s a quote from the documentation:
The real challenge is producing EPUB and MOBI output. The trick is to (1) create a self-contained HTML page with embedded math, (2) include the amazing MathJax JavaScript library, configured to render math as SVG images, (3) hit the page with the headless PhantomJS browser to force MathJax to render the math (including any equation numbers) as SVGs, (4) extract self-contained SVGs from the rendered pages, and (5) use Inkscape to convert the SVGs to PNGs for inclusion in EPUB and MOBI books. Easy, right? In fact, no—it was excruciating and required excessive amounts of profanity to achieve. But it’s done, so ha.
Stay tuned for .epub version of the books in the No BS guide series.
Math makes you cry? Try SymPy!
This summer I wrote a short SymPy tutorial that illustrates how a computer
algebra system can help you understand math and physics. Using SymPy you can solve all kinds of math problems, painlessly.
Check it:

Sympy tutorial (PDF, 12 pages)
Print this out, and try the examples using live.sympy.org. The topics covered are: high school math, calculus, mechanics, and linear algebra.
SymPy makes all math and physics calculation easy to handle, it can even make them fun! Learn the commands and you’ll do well on all your homework problems. Best of all, sympy is free and open source software so your learning and your calculations won’t cost you a dime!
Linear algebra concept maps
I spent the last week drawing. More specifically, drawing in concept space. Drawing concept maps for the linear algebra book.
Without going into too much details, the context is that the old concept map was too overloaded with information, so I decided to redo it. I had to split the concept map on three pages, because there’s a lot of stuff to cover. Check it out.
Math basics and how they relate to geometric and computational aspects of linear algebra
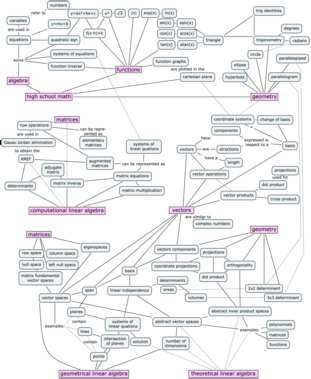
The skills from high school math you need to “import” to your study of linear algebra are geometry, functions, and the tricks for solving systems of equations (e.g. the values $x$ and $y$ that simultaneously satisfy the equations $x+y=3$ and $3x+y=5$ are $x=1$ and $y=2$.)
The first thing you’ll learn in linear algebra is the Gauss–Jordan elimination procedure, which is a systematic approach for solving systems of $n$ equations with $n$ unknowns. You’ll also learn how to compute matrix products, matrix determinants, and matrix inverses. This is all part of Chapter 3 in the book.
In Chapter 4, we’ll learn about vector spaces and subspaces. Specifically, we’ll discuss points in $\mathbb{R}^3$, lines in $\mathbb{R}^3$, planes in $\mathbb{R}^3$, and $\mathbb{R}^3$ itself. The basic computational skills you picked up in Chapter 3 can be used to solve interesting geometric problems in vectors spaces with any number of dimensions $\mathbb{R}^n$.
Linear transformations and theoretical topics
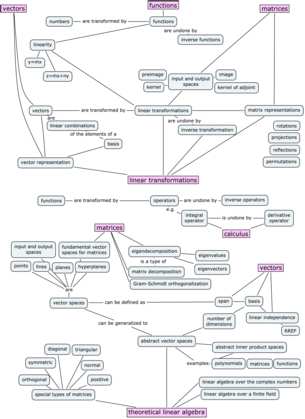
The concept of a linear transformation $T:\mathbb{R}^n \to \mathbb{R}^m$ is the extension of the idea of a function of a real variable $f:\mathbb{R} \to \mathbb{R}$. Linear transformations are linear functions that take $n$-vectors as inputs and produce $m$-vectors as outputs.
Understanding linear transformations is synonymous with understanding linear algebra. There are many properties of a linear transformation that we might want to study. The practical side of linear transformations is their nature as a vector-upgrade to your existing skill set of modelling the world with functions. You’ll also learn how to study, categorize, and understand linear transformations using new theoretical tools like eigenvalues and eigenvectors.
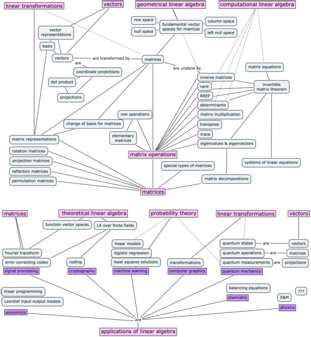
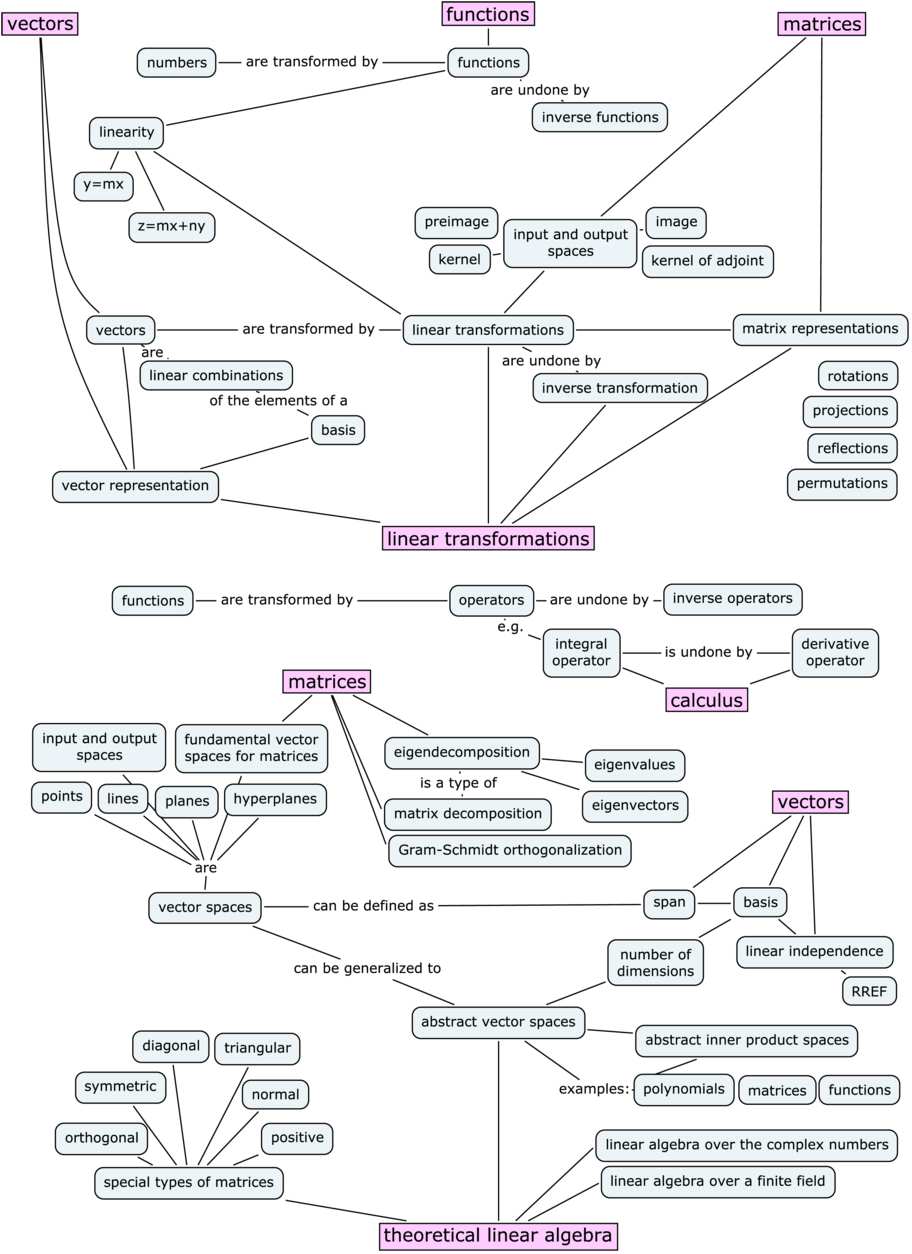
Matrices and applications
{kind=link}
{kind=link}
{kind=link}
Another fundamental idea in linear algebra is the equivalence between linear transformations $T:\mathbb{R}^n \to \mathbb{R}^m$ and matrices $M \in \mathbb{R}^{m\times n}$. Specifically, the abstract idea of a linear transformation $T:\mathbb{R}^n \to \mathbb{R}^m$, when we fix a particular choice of basis $B_i$ for the input space and $B_o$ for the output space of $T$, can be represented as a matrix of coefficients $_{B_o}[M_T]_{B_i} \in \mathbb{R}^{m\times n}$. The precise mathematical term for this equivalence is isomorphism. The isomorphism between linear transformations and their matrix representations means we can characterize the properties of a linear transformation by analyzing its matrix representation.
Chapter 7 in the book contains a collection of short “applications essays” that describe how linear algebra is applied to various domains of science and business. Chapter 8 is a mini-intro to probability theory and Chapter 9 is an intro course on quantum mechanics. All the applications are completely optional, but I guarantee you’ll enjoy reading them. The power of linear algebra made manifest.
If you’re a seasoned blog reader, and you just finished reading this post, I know what you’re feeling… a moment of anxiety goes over you—is a popup asking you to sign up going to show up from somewhere, is there going to be a call to action of some sort?
Nope.
Problem sets ready
Sometime in mid-December I set out to create problem sets for the book. My friend Nizar Kezzo offered to help me write the exercises for Chapter 2 and Chapter 4 and I made a plan to modernize the calculus questions a bit and quickly write a few more questions and be done in a couple of weeks.
That was four months ago! Clearly, I was optimistic (read unrealistic) about my productivity. Nizar did his part right on schedule, but it took me forever to write nice questions for the other chapters and to proofread everything. After all, if the book is no bullshit, the problem sets must also be no bullshit. I’m quite happy with the results!
noBS problem sets: letter format or 2up format.
Please, if you find any typos or mistakes in the problem sets, drop me a line so I can fix them before v4.1 goes to print.
Tools
In addition to work on the problem sets, I also made some updates to the main text. I also developed some scripts to use in combination with latexdiff to filter only pages with changes. This automation saved me a lot of time as I didn’t have to page through 400pp of text, but only see the subset of the pages that had changes in them.
If you would like to see the changes made to the book from v4.0 to v4.1 beta, check out noBSdiff_v4.0_v4.1beta.pdf.
Future
Today I handed over the problems to my editor and once she has taken a look at them, I’ll merge the problems into the book and release v4.1. The coming months will be focussed on the business side. I know I keep saying that, but now I think the book is solid and complete so I will be much more confident when dealing with distributors and bookstores. Let’s scale this!
Linear algebra tutorial in four pages
I just pushed an update to the Linear algebra explained in four pages tutorial.

Anyone who has an exam with lots of $A\vec{x}=\vec{b}$ stuff on it coming up should check it out because it covers: vector operations, matrix operations, linear transformations(matrix-vector product, fundamental vector spaces, matrix representation), solving systems of linear equations (the RREF stuff), matrix inverse, eigenvalues.
UPDATE: I found another excellent tutorial which I think you should also read, especially if you are a visual person. A Geometric Review of Linear Algebra by Prof. Eero P. Simoncelli (discuss on HN if you are a procrastinating person). If you’re a studious person, you’ll also go to en.wikibooks.org/wiki/Linear_Algebra and practice solving problems. To become a powerful person, don’t look at the solution until you’ve attempted the problem (with pen and paper) for at least five minutes.
UPDATE: I found some other useful short tutorials, like this short review of linear algebra from Stanford and another one from Boulder which both cover interesting details and bring a new perspective.